Overview
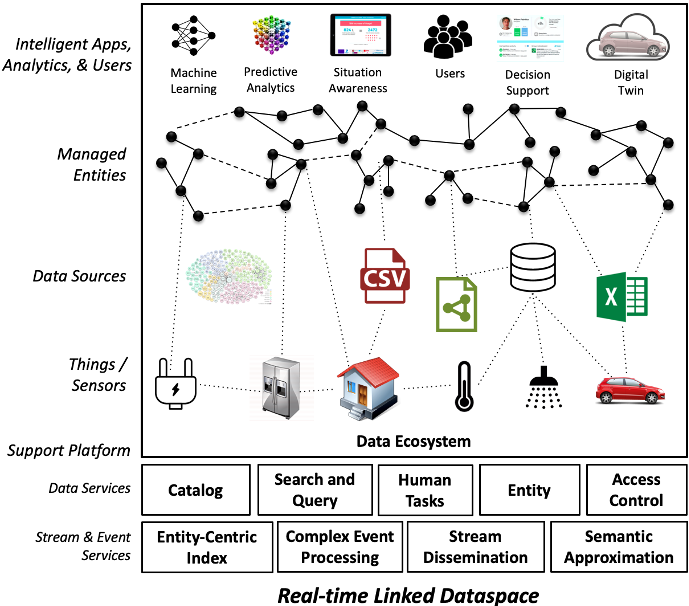
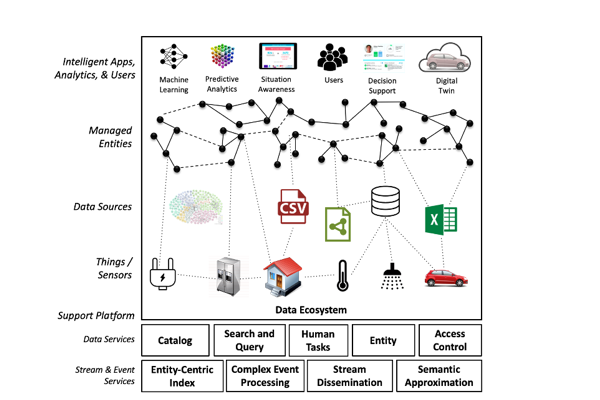
The Real-time Linked Dataspace (RLD) is an enabling platform for data management for intelligent systems within smart environments that combines the pay-as-you-go paradigm of dataspaces, linked data, and knowledge graphs with entity-centric real-time query capabilities.
The RLD contains all the relevant information within a data ecosystem including things, sensors, and data sources and has the responsibility for managing the relationships among these participants.
It manages sources without presuming a pre-existing semantic integration among them using specialised dataspace support services for loose administrative proximity and semantic integration for event and stream systems. Support services leverage approximate and best-effort techniques and operate under a 5 star model for “pay-as-you-go” incremental data management.
Key Concepts
Key Conepts on Datspaces and Real-time Linked Dataspaces
Data Ecosystems for Intelligent Systems
Data ecosystems present new challenges to the design of intelligent systems that require a reconsideration of how we deal with the data management needs of large-scale data-rich smart environments. To understand the emerging data management challenges, we explore the design of intelligent systems within smart environments and the need to support knowledge flows within data ecosystems.
learn more
A Data Platform for Intelligent Systems
A data platform focuses on the secure and trusted data sharing among a group of participants (e.g. industrial consortiums sharing private or commercially sensitive data) within a clear legal framework. Within a smart environment, a data platform would have support continuous, coordinated data flows, seamlessly moving data among intelligent systems.
learn more
Principles and Practices
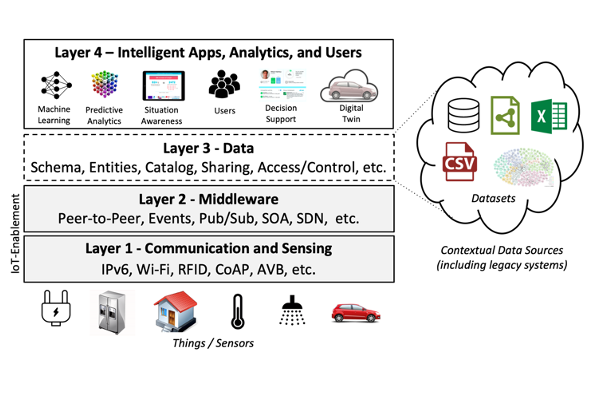
Dataspace are an emerging approach to data management that recognises that in large-scale integration scenarios, involving thousands of data sources, it is difficult and expensive to obtain an upfront unifying schema across all sources. A Real-time Linked Dataspace is a specialised dataspace that manages and processes large-scale distributed heterogeneous collections of streams, events and data sources in a Smart Environment.
learn more

Pay as you go Services
Within a Real-time Linked Dataspace, the pay-as-you-go approach to data management is complemented with a principled tiered approach to the design of support services where an increase in the level of active data management has a corresponding increase in the associated effort. This tiered approach to data management provides flexibility by reducing the initial effort and barriers to joining the dataspace.
learn more
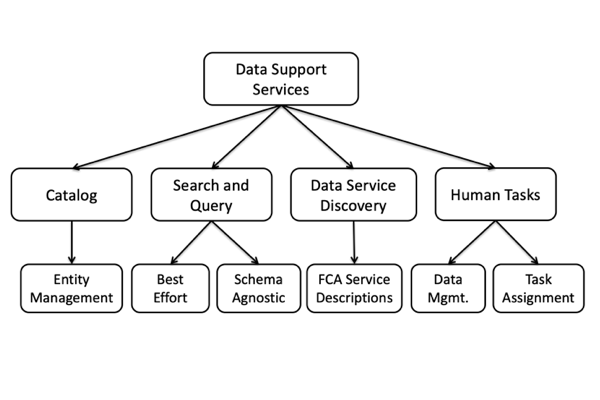
Data Support Services
Enhanced data support services have been developed for the Real-time Linked Dataspace to support data management for intelligent systems within smart environments. These services support a real-time dataspace system to get up and running with a low overhead for administrative setup costs (e.g. catalog, entity management, search and query, and data service discovery).
learn more
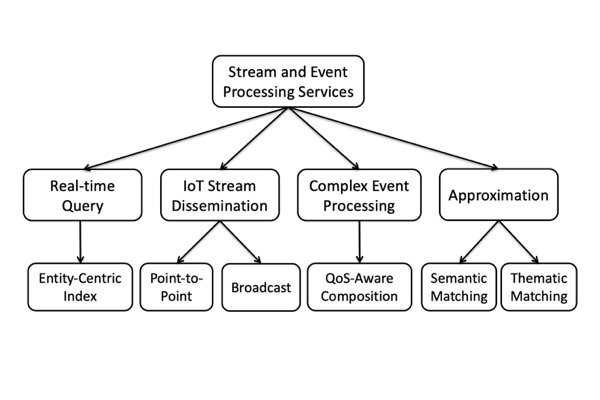
Stream and Event Processing Services
We explore new techniques to support approximate and best-effort stream and event processing services for Real-time Linked Dataspaces, which support data processing support services that follow the data management philosophy of dataspaces and meet the requirements of real-time data processing.
learn more
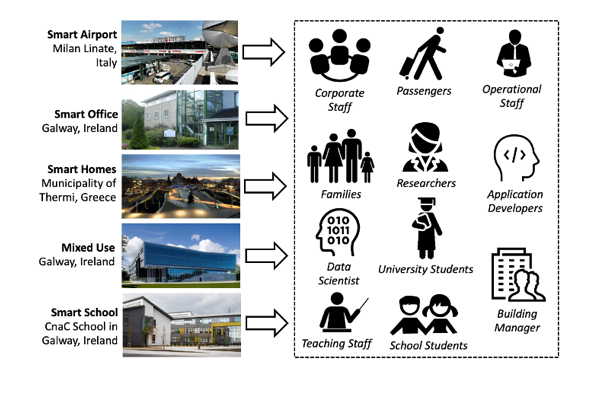
Smart Environment Pilots
Over the past number of years, we have been involved in a number of projects concerned with investigating the use of a Real-time Linked Dataspace as a data platform for intelligent systems within smart environments, specifically targeting intelligent systems for smart energy and water management.
learn more
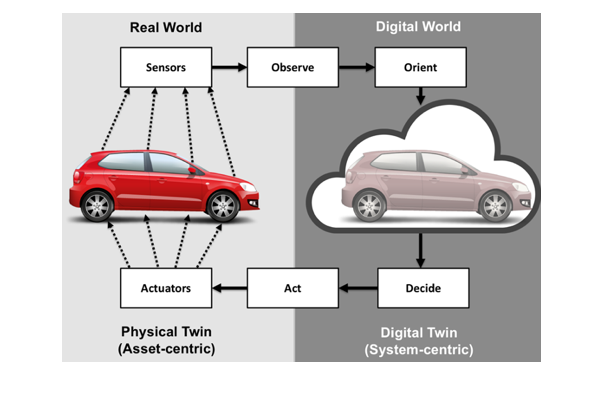
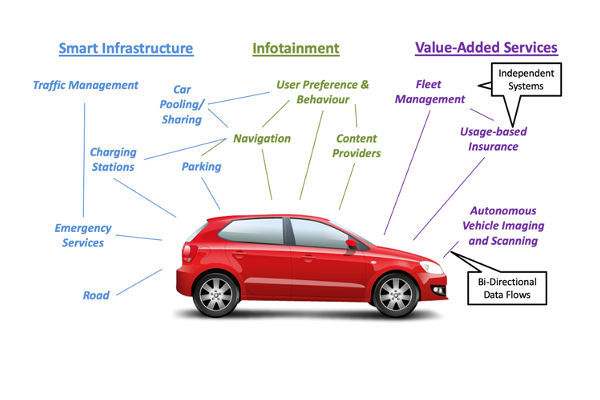
Digital Twins and Intelligent Applications
We explore the use of Real-time Linked Dataspaces within real-world smart environments by demonstrating its role in enabling digital twins and intelligent applications for water and energy management systems.
learn more

Research Directions
Research areas which are essential to enabling the next-generation of dataspaces, data ecosystems, intelligent systems including decentralised support services, support for multimedia data, trusted data sharing, governance and economic models, incremental systems engineering, and human-centricity.
learn more
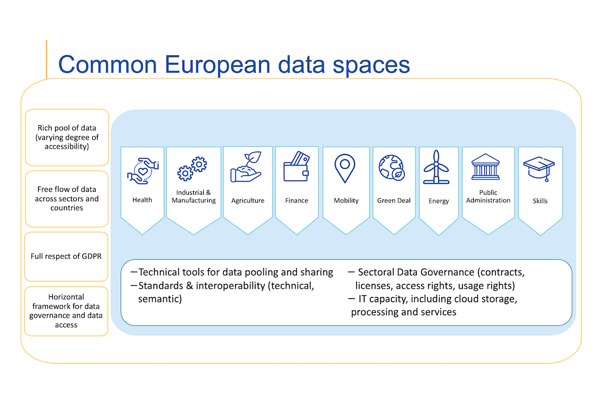
Common European Data Spaces
The European strategy for data aims at creating a single market for data that will ensure Europe’s global competitiveness and data sovereignty. Common European data spaces will ensure that more data becomes available for use in the economy and society, while keeping companies and individuals who generate the data in control.
learn more

BDVA Data Sharing Spaces
The BDVA position paper “Towards a European Data Sharing Space: Enabling data exchange and unlocking AI potential” supports the dialog among European and national policy makers, industry, research, public sector and civic society in the definition of a common roadmap for the development and adoption of a pan-European Data Sharing Space and to guide public and private investments in this area in the next Multiannual Financial Framework.learn more

From Data Platforms to Dataspaces [Presentation]
A recent presentation on the use of Dataspaces as a data platform for IoT-enabled Smart Environments. Provides a high-level overview of the our work Real-time Linked Dataspaces.
learn more
Foreword
In Lewis Carroll’s Through the Looking-Glass the Red Queen explained to Alice the nature of Looking-Glass Land “Now, here, you see, it takes all the running you can do, to keep in the same place”. Van Valen coined the “Red Queen” hypothesis where populations have to “run” an evolutionary race in order to stay in the same place, or else go extinct. Within our Digital Universe, we have a Digital Red Queen, with a race between our ability to create masses of data and our ability to manage it effectively and effectively.
Over the last quarter of a century, we have both run this race with our work in the corporate worlds of Google and Verizon to the ivory towers of MIT and the University of Washington. We were both extremely interested in the problems of data integration at scale within ecosystems and have proposed approaches for doing so. Naturally, we felt more than a little curious to see what Ed and his team had produced.
In the decade since our original works on ecosystems and dataspaces, we have seen new data management needs arise from the mass migration of applications from batch processing paradigms to real-time processing. This sets the scene for the book as it introduces “Real-time” dataspaces to enable data flows within ecosystems of intelligent systems. Within these covers, you will find a technical vision, new techniques, and deep insight for both theory and practice of dataspaces for real-time data. The book brings us on a journey from the lab to the field by developing new pioneering best-effort techniques for real-time data management and validates their use within an excellent choice of an application domain, not just resource management but specifically sustainability. This body of work illustrates how the dataspace paradigm has evolved and the transformative potential of leveraging data ecosystems to drive value within intelligent systems. The work goes beyond a purely technical perspective and exposes the critical social and organizational aspects of managing data ecosystems for the collective benefit of the participants.
We are delighted to write this forward to a book that will influence the thinking on the design of data infrastructures as a key enabler of data ecosystems, intelligent systems, and smart environments. It sets out a clear path for the design of data platforms based on dataspaces with support for best-effort real-time data processing techniques. This impressive body of work illustrates the power that data-driven systems have to improve the sustainability of our planets complex ecosystems, both Natural and Digital.

Michael L. Brodie
MIT, Cambridge, MA, USA

Alon Halevy
Facebook AI, Menlo Park, CA, USA
Preface
Around 2012 I started to investigate the potential of data-driven intelligent systems for sustainability. I was (and still am) very motivated by the potential of the Internet of Things (IoT), data analytics, and artificial intelligence to create intelligent systems that can contribute to a sustainable society. As a computer scientist with a background in distributed systems and data management, I felt I could make a modest contribution to the design and construction of these intelligent systems. There was significant potential for data-driven and artificial intelligence techniques to power intelligent systems for sustainability. However, for these approaches to be viable, they would need to be cost-effective and deployable. Working with my industrial collaborations, it was clear that a critical barrier to the adoption of intelligent systems was, and still is, the high upfront costs associated with data sharing and integration. For decades we have seen the consequences of data silos within Enterprises with estimates of 50–80% of the costs of data projects going to data integration and preparation activities. This limits large-scale data management projects to large organisations that have the necessary expertise and resources. This needs to change if we want a broad effort for sustainability that enables smaller stakeholders to engage and leverage the value available in data.
Datafication driven by IoT-based digital infrastructure is leading to an ecosystem of data which can be exploited to transform our world. Typically, IoT data has the most value when it can be processed on-the-fly and with low-latency. However, the current wave of datafication is leading to increasing “data silos.” In 2012, the IoT was predicted to have 25 billion connected devices by 2020; current estimates are now for over 75 billion connected devices by 2025. What was evident in 2012, and is even more apparent today, is that we need a fundamental transformation in how we manage the data ecosystem surrounding intelligent systems in smart environments. Traditional approaches to data management will not be sufficient. We need a paradigm shift as significant as the move to relational data management in the 1970s to provide an alternative to the current top-down, centralised models of data management.
In the first two decades of the twenty-first century, a recognition emerged among researchers and practitioners that a new class of information management and processing systems was needed to support diverse distributed real-time applications. Michael Brodie has been a Prophet of the data integration challenges within ecosystems where thousands of semantically heterogeneous databases need to be managed and integrated collectively. These information ecosystems necessitate a transformation in how data is managed and shared among intelligent systems. Halevy, Franklin, and Maier recognised that in large-scale integration scenarios, involving thousands of data sources (such as ecosystems), it is difficult and expensive to obtain an upfront unifying schema across all sources. They introduced the paradigm of Dataspaces that shifts the emphasis to providing support for the co-existence of heterogeneous data that does not require a significant upfront investment into a unifying schema. The concepts of ecosystems and dataspaces were absorbing, and I was excited by the potential of “best-effort” approaches. I felt there might be a possible connection to the Pareto Principle.
The Pareto Principle (or the 80/20 rule) has wide application in many areas from economics and market analysis to business strategy, where it has been observed that 20% of the effort delivers 80% of the results. Within computer science, this principle has been observed within many problems from fixing bugs to writing code. The principle can help us to prioritise actions, for example, focus on the 20% of software bugs that cause 80% of the system crashes. The power of the principle has always fascinated me, and the dataspaces paradigm can unlock its power within the data realm. The pay-as-you-go model allows participants in the dataspace to focus on high-value data and tackle the “long tail” of data on an as-needed basis. This was the genesis of this work.
This book explores the dataspace paradigm as an alternative best-effort approach to data management with data ecosystems. It establishes the theoretical foundations and principles of Real-time Linked Dataspaces as a data platform for intelligent systems, and introduces a set of specialised best-effort techniques and models to enable loose administrative proximity and semantic integration for managing and processing events and streams.
Readers of this book will gain a detailed understanding of how the dataspace paradigm is used to enable data ecosystems for intelligent systems within smart environments. The reader is brought from establishing the fundamental theory and the creation of new techniques needed for support services, to the experience gained from delivering real-world intelligent systems for smart cities, buildings, energy, water, and mobility.
The book is of interest to three key audiences. First are researchers and graduate students in the fields of data management, big data, IoT, and intelligent systems with interest in state-of-the-art techniques for approximate and best-effort approaches to incremental data management. Second, the book provides useful insights to practitioners that need to create advanced data management platforms for intelligent systems, smart environments, and data ecosystems. Practitioners will learn about designing incremental data management architectures and techniques that are grounded in theory and informed by the experience of rigorous deployments within real-world settings. Third, researchers and practitioners involved in interdisciplinary and transdisciplinary “Smart” projects will gain insights on the design and operation of data-intensive socio-technical intelligent systems.
The book is structured as follows: Part I: Fundamentals and Concepts details the motivation and core concepts of Real-time Linked Dataspaces. This part establishes the need for an evolution of data management techniques to meet the challenges of enabling a data ecosystem for intelligent systems within smart environments. It details the fundamental concepts of Dataspaces and the need for specialisation for processing dynamic real-time data. Part II: Data Support Services explores the design and evaluation of critical services within the Real-time Linked Dataspace, including catalog, entity management, query and search, data service discovery, and human-in-the-loop. Part III: Stream and Event Processing Services details the design and evaluation of the specialised techniques created for real-time support services including complex event processing, event service composition, stream dissemination, stream matching, and approximate semantic matching. Part IV: Intelligent Systems and Applications explores the use of Real-time Linked Dataspaces within real-world smart environments by demonstrating its role in enabling intelligent water and energy management systems through the development of IoT-enabled digital twins, enhanced user experience, and autonomic source selection for advanced predictive analytics. Finally, Part V: Future Directions details research challenges for dataspaces, data ecosystems, and intelligent systems.
Forward-thinking societies will see the provision of digital infrastructure as a shared societal service in the same way as water, sanitation, and healthcare. With few exceptions, our current large-scale data infrastructures are beyond the reach of small organisations who cannot deal with the complexity of data management and the high costs associated with data infrastructure. It is clear we desperately need new approaches to support the complex data ecosystems our “smart” society is creating. This vision demands a fundamental shift in how to design large-scale data ecosystem infrastructure to unlock the power of a Pareto effect for data. I believe this book is a step in that direction.
Edward Curry
Open Access Book
This open access book explores the dataspace paradigm as a best-effort approach to data management within data ecosystems. It establishes the theoretical foundations and principles of real-time linked dataspaces as a data platform for intelligent systems. The book introduces a set of specialized best-effort techniques and models to enable loose administrative proximity and semantic integration for managing and processing events and streams.
The book is divided into five major parts: Part I “Fundamentals and Concepts” details the motivation behind and core concepts of real-time linked dataspaces, and establishes the need to evolve data management techniques in order to meet the challenges of enabling data ecosystems for intelligent systems within smart environments. Further, it explains the fundamental concepts of dataspaces and the need for specialization in the processing of dynamic real-time data. Part II “Data Support Services” explores the design and evaluation of critical services, including catalog, entity management, query and search, data service discovery, and human-in-the-loop. In turn, Part III “Stream and Event Processing Services” addresses the design and evaluation of the specialized techniques created for real-time support services including complex event processing, event service composition, stream dissemination, stream matching, and approximate semantic matching. Part IV “Intelligent Systems and Applications” explores the use of real-time linked dataspaces within real-world smart environments. In closing, Part V “Future Directions” outlines future research challenges for dataspaces, data ecosystems, and intelligent systems.
Readers will gain a detailed understanding of how the dataspace paradigm is now being used to enable data ecosystems for intelligent systems within smart environments.
Edward Curry
Edward Curry is Vice President of the Big Data Value Association (www.BDVA.eu) a non-profit industry-led organisation with the objective of increasing the competitiveness of European Companies with data-driven innovation. Edward is a research leader at the Insight Centre for Data Analytics (www.insight-centre.org) and a funded investigator at LERO The Irish Software Research Centre (www.lero.ie). Edward has worked extensively with industry and government advising on the adoption patterns, practicalities, and benefits of new technologies. Edward has published over 120 scientific articles in journals, books, and international conferences. He has presented at numerous events and has given invited talks at Berkeley, Stanford, and MIT. In 2010, he was a guest speaker at the MIT Sloan CIO Symposium to an audience of 600+ CIOs and senior IT executives. His research projects include studies of smart cities, energy intelligence, semantic information management, event-based systems, and collaborative data management. He is a member of the scientific leadership committee of Insight, and a Lecturer in Informatics at the National University of Ireland Galway (NUIG). He has a Ph.D. from the National University of Ireland Galway.
Contact